Lumina-T2X is a unified
framework for Text to Any Modality
Lumina-T2X is a unified
framework for Text to Any Modality
It helps you build a Generation Model with any modailty. Fast.
lumina infer "A snowman of ..."
Lumina-T2I - Image Generation
Creative Super-resolution as Image Editing


Arbitrary Aspect Ratio Generation

Consistent-Style Generation

Arbitrary Aspect Ratio Generation

Resolution Extrapolation

Compositional Generation

High-res. Image Editing

Compositional Generation
Creative Super-resolution as Image Editing
1 of 9
Architecture 🏗️
We are excited to unveil Lumina-T2X, a unified framework that seamlessly transforms text into a variety of modalities, including images, videos, multi-view images, and audio.
At the heart of Lumina-T2X lies the Flow-based Large Diffusion Transformer (Flag-DiT), which supports up to 7B parameters and 512K token generation. We will be open-sourcing both the training codes and pre-trained models to foster further research and development.
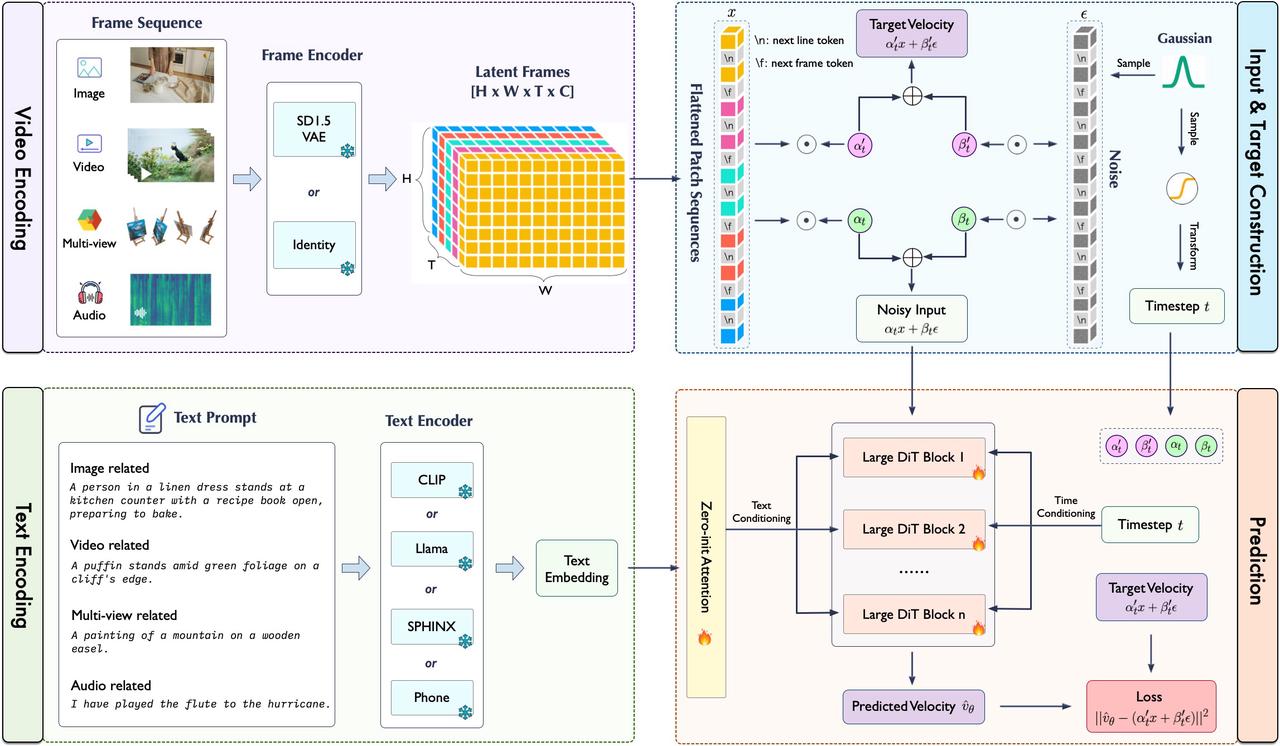
Flow-based Large Diffusion Transformer (Flag-DiT)
Lumina-T2X is trained with the flow matching objective and is equipped with many techniques, such as RoPE, RMSNorm, and KQ-norm, demonstrating faster training convergence, stable training dynamics, and a simplified pipeline.
Any Modalities with one Framework
the model can encode any modality, including mages, videos, multi-views of 3D objects, and spectrograms into a unified 1-D token sequence at any resolution, aspect ratio, and temporal duration.
Any Aspect Ratio with one framework
Lumina-T2X can naturally encode any modality—regardless of resolution, aspect ratios, and temporal durations into a unified 1-D token sequence akin to LLMs, by utilizing Flag-DiT with text conditioning to iteratively transform noise into outputs across any modality, resolution, and duration during inference time.
Any Duration with one fraemwork
By introducing the nextline and nextframe tokens, our model can support resolution extrapolation, i.e., generating images/videos with out-of-domain resolutions not encountered during training.
Low Training Resource
Our Large-DiT reduces the total number of training iterations needed, thus minimizing overall training time and computational resources. the default Lumina-T2I configuration, equipped with a 5B Flag-DiT and a 7B LLaMA as the text encoder, requires only 20% of the computational resources needed by Pixelart-$\alpha$.